Data Ingestion
This page will give you all the tools to make your data fast to read to make your UDFs more responsive.
What is this page about?
The whole purpose of Fused is to speed up data science pipelines. To make this happen we need the data we're working with to be responsive, regardless of the dataset. The ideal solution is to have all of our data sitting in RAM right next to our compute, but in real-world applications:
- Datasets (especially geospatial data) can be in the Tb or Pb range which rarely in storage, let alone RAM
- Compute needs to be scaled up and down depending on workloads.
One solution to this is to build data around Cloud Optimized formats: Data lives in the cloud but also leverages file formats that are fast to access. Just putting a .zip file than needs to be uncompressed every time on an S3 bucket still makes reading it very slow. Our ingested data should be:
- On the cloud so dataset size doesn't matter (AWS S3, Google Cloud Storage, etc.)
- Partitioned (broken down into smaller pieces that are fast to retrieve so we can load only sections of the dataset we need)
This makes it fast to read for any UDF (and any other cloud operation), so developing UDFs in Workbench UDF Builder & running UDFs is a lot faster & responsive!
When is ingestion needed?
You don't always need to ingest your file into a cloud, geo-partitioned format. There are a few situation when it might be simpler & faster to just load your data.
Small files (< 100Mb ) that are fast to open (already in .parquet for example) that you only read once (note that it might be read 1x in your UDF but your UDF might be run many times)
Example of data you should ingest: 1Gb .zip of shapefile
.zipmeans you need to unzip your file each time you open it and then read it. This slows down working with the data- shapefile contains multiple files, it isn't the fastest to read
Example of data you don't need to ingest: 50Mb .parquet
- Even if the data isn't geo-partitioned, loading this data should be fast enough to make any UDF fast
File Formats
For rasters (images)
For images (like satellite images) we recommend using Cloud Optimized GeoTiffs (COGs). To paraphrase the Cloud Native Geo guide on them:
Cloud-Optimized GeoTIFF (COG), a raster format, is a variant of the TIFF image format that specifies a particular layout of internal data in the GeoTIFF specification to allow for optimized (subsetted or aggregated) access over a network for display or data reading
Fused does not (yet) have a build-in tool to ingest raster data. We suggest you create COGs yourself, for example by using gdal's built-in options or cogger
Cloud Optimized GeoTiffs have multiple different features making them particularly interesting for cloud native applications, namely:
- Tiling: Images are split into smaller tiles that can be individually accessed, making getting only parts of data a lot faster.
- Overviews: Pre-rendered images of lower zoom levels of images. This makes displaying images at different zoom levels a lot faster
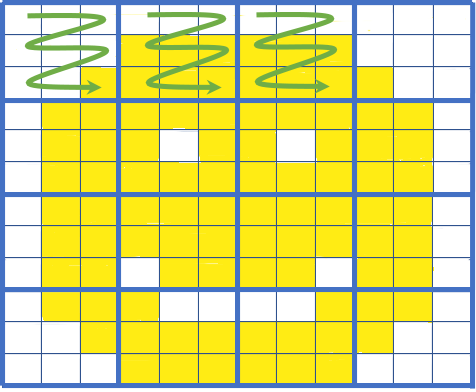
A simple visual of COG tiling: If we only need the top left part of the image we can fetch only those tiles (green arrows). Image courtesy of Element 84's blog on COGs
- Element84 wrote a simple explainer of what Cloud Optimized GeoTiffs are with great visuals
- Cloud Optimized Geotiff spec dedicated website
- Cloud Optimized Geotiff page on Cloud Native Geo guide
For vectors (tables)
To handle vector data such as pandas DataFrames or geopandas GeoDataFrames we recommend using GeoParquet files. To (once again) paraphrase the Cloud Native Geo guide:
GeoParquet is an encoding for how to store geospatial vector data (point, lines, polygons) in Apache Parquet, a popular columnar storage format for tabular data.

Image credit from the Cloud Native Geo slideshow
Refer to the next section to see all the details of how to ingest your data with Fused's built-in fused.ingest() to make the most out of geoparquet
Additional resources
- Read the Cloud-Optimized Geospatial Formats Guide written by the Cloud Native Geo Org about why we need Cloud Native formats
- Friend of Fused Kyle Barron did an interview about Cloud Native Geospatial Formats. Kyle provides simple introductions to some cloud native formats like
GeoParquet